3D Skeleton Tracking & Pose Recognition with OPT: How They Work…
OpenPTrack V2 (Gnocchi) introduces a new 3D pose tracking and pose recognition feature.
(Press play to watch videos. Click on any still for a larger view.)
The algorithm behind this skeleton tracking feature can be explained by this picture: 
Each sensor within the field provides three types of data: color (RGB) images, depth images, and some calibration parameters. This information is enough to build 3D point clouds, the core data OPT uses.
The data flow coming from each sensor is intercepted by a skeleton detector (orange box in the picture above), with the goal of understanding the skeletons’ locations by considering their color images. The library being used to compute this information is OpenPose, an open source multi-body pose estimation algorithm. Once the skeletons are located, they can be drawn onto each image. However, since we also have 3D data, the point cloud information and just-computed 2D skeletons are combined, projecting them in the 3D world. The single-view detector takes the color, depth and geometric properties of a sensor as input, and returns the set of 3D skeletons as output.
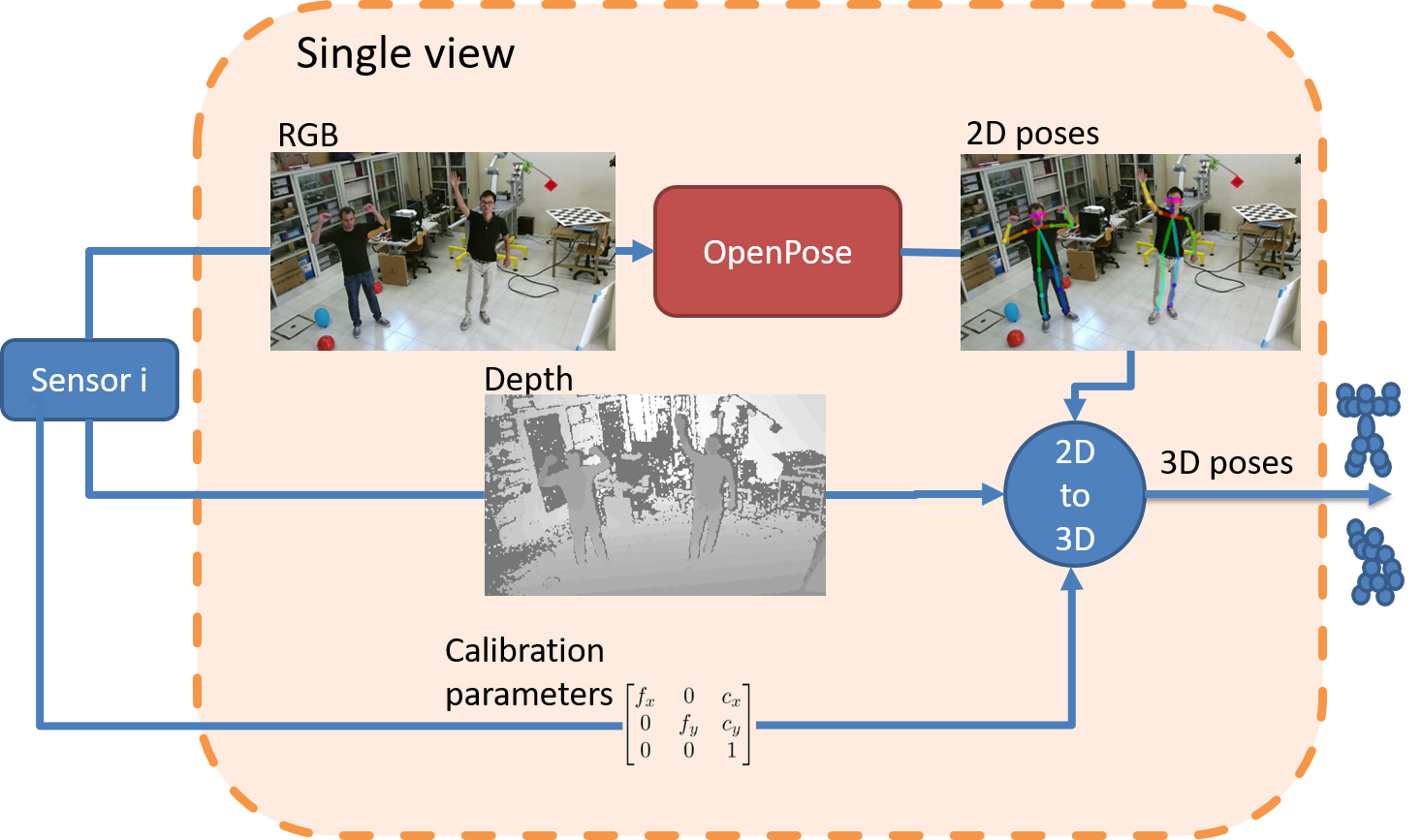
By using a single-view detector for each sensor in the network, we are able to send a set of 3D skeletons to a central computer, for the mathematical operations to convert the skeletons in the right coordinate frame (information is always available since the calibration of the camera network is performed beforehand). The central computer also fuses the different skeletons. Time matters; the new skeletons arrive just in time to contribute in two mutually exclusive ways:
- They belong to people who just entered the tracking space, and the system will generate a new track for them, or:
- They belong to people who were already in the tracking space, and the system should update the positions with the new data.
The system should be able to detect whether a skeleton which was in the space has no new data, i.e. the person left the tracking space. In this case, its track should be removed.
The math behind this computation is called the “Hungarian algorithm”. We’re not going into detail here, but if you are a curious nerd like us, please check out our paper.
By using the system as explained, you can get results like this (which are in real time!):

The 3D poses are also sent via UDP in a comfy JSON format, ready to be read and used by any third-party application. Check the wiki to learn more!
Real-time poses are helpful in building rich Human Computer Interaction systems, but recognizing poses as well is even better. To this end, OpenPTrack embeds a pose recognition algorithm which is independent from the shape and size of a person, since it is based on the position of arms and legs.
This trick is possible thanks to a frontalization in standard poses. Given a 3D skeleton, its heading direction (orientation) is obtained by exploiting a simple linear algebra idea: a crossproduct of the vectors linking the torso and each shoulder:
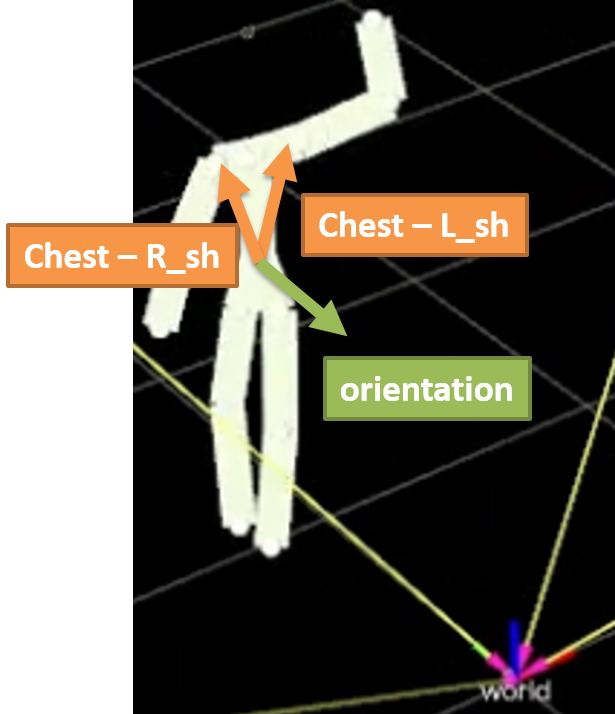
Since we are still in a calibrated camera network, and the data always refers to a common world reference system, it is possible to compute a displacement angle between the heading direction and the xOy plane of the world (i.e., the ground plane).
Given this angle and the fact that we are addicted to mathematical trickery as roto-translational matrices, we can roto-translate the joints of each skeleton in the scene and place them at the origin. At the same time, we can perform another important transformation: Each link is standardized to a unit length. In this way, the frontal standard pose of children, kids and adults are all directly comparable; heights and shape of bodies do not matter.
The following video shows an example of the computation of the standard pose. The standard pose can be seen as the little skeleton at the center of the screen; the right arm is colored in red to show that there is no flipping:
Pose recognition is performed by means of the calculation of a distance between the current standard pose and a set of template galleries. A template is simply a pose with a tag name to be recognized. OpenPTrack allows registering an unlimited number of templates. (Take a look at the wiki on how to do this). Recording a new pose to be recognized is not difficult and is totally body driven! A person can even act as a model to record another person.
The pose recognition module comes with a set of 3 pre-recorded poses that are always recognized, i.e: “right_arm_up,” “arms_mid,” and “left_arm_pointing.”
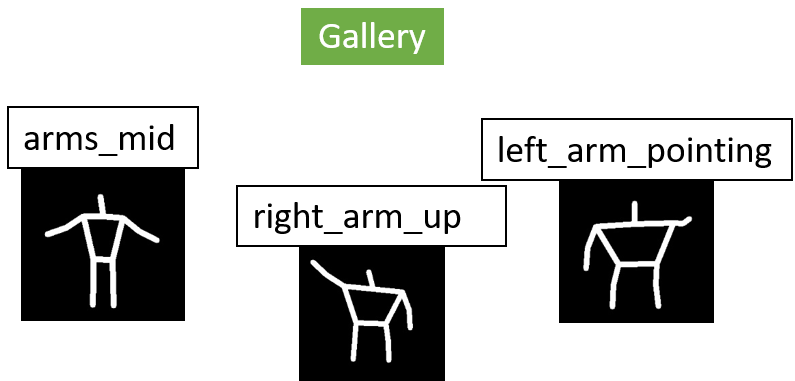
The pose prediction phase is performed by calculating a signature of the current skeleton in a frontal standard pose, and comparing this signature to the ones in the gallery (i.e., the templates). If the closest distance is also below a threshold, then the pose is recognized. The information taken into account in this phase is only the position of the arms, and optionally of the legs. This video shows results you can obtain using OpenPTrack:
If you want to know more about the pose recognition module, please check out our paper.